PDF转EPUB格式电子书经验总结
根据本人将PDF转换为EPUB电子书的经验,总结整理了这篇文章,因本人水平有限,难免有错误和不足之处,望大家及时批评指正。
写这篇文章时,假定读者已经会使用文中所列出软件的基本操作,比如怎样用Notepad++打开HTML文件,如何使用PDF Password
Remover(这个软件很简单,稍有电脑操作基础的人打开后就知道怎么做)。另外读者需要对ePubBuilder的操作比较了解。
本文主要讨论图文并茂、非扫描版的PDF文档。对于扫描版PDF文件,如果是漫画一类的,可以直接用Adobe
Acrobat转化为图片制作EPUB,如果是文字形式的扫描电子书,可以使用OCR软件识别以转化成文字(ABBYY
FineReader识别效果相对较好),但OCR识别中文准确率不够高,部分无法识别的汉字需要人工输入。对于纯文本形式的PDF,直接保存为TXT,然后转换就可以。如果文字无法复制,可以用PDF
Password Remover解密,具体请参考本文的PDF解密部分。
以下摘自百度百科:
PDF是Portable Document Format(便携文件格式)的缩写,是一种电子文件格式,与操作系统平台无关,由Adobe
公司开发而成。PDF
文件是以PostScript语言图象模型为基础,无论在哪种打印机上都可保证精确的颜色和准确的打印效果,即PDF会忠实地再现原稿的每一个字符、颜色以及图象。
PDF主要由三项技术组成:
· 衍生自PostScript,可以说是PostScript的缩小版;
· 字型嵌入系统,可使字型随文件一起传输;
· 资料压缩及传输系统。
PDF文件结构主要可以分为四个部分:
1.首部
2.文件体
3. 交叉引用表
4.尾部
一方面,PDF格式作为印前出版的工业标准,由于其排版相对复杂,文件内容也有比较复杂,比如PDF可以内嵌特殊字体,可以很自由的保存每个图片、文本对象的绝对位置,而另一方面,EPUB采用类似网页格式的XML标准,即使增加了CSS样式表的支持,排版效果还是远难及PDF,因此想把排版优良的PDF电子书完美地转换成EPUB格式,相对比较复杂。一些正版收费阅读器会推出一些排版质量很高的EPUB,我试用过,排版确实不错,但是那只有在非常精心的制作下才能得出,对于我们转换PDF的人来说,是很不现实的,而且那些电子书一般收费是比较高的,应该还有授权限制,不可能共享出来让大家都能用(这些文件只有在特定应用中登录特定账号后才能打开,复制给别人就打不开了)。
可能要用到的所有软件:
PDF Password Remover 3.0
Adobe Acrobat
Chrome浏览器(其他浏览器应该也行)
Notepad++
Microsoft Word
WPS
数码照片压缩大师
ePubBuilder
大致思路是首先解除密码限制,然后导出为HTML格式,去除无关信息、修正乱码等,然后用ePubBuilder导入,完善书籍信息,分章节,自己用阅读器打开检查有无严重错误,然后发布。为什么要转为HTML,因为这种格式完全开源,好处理,出错率低,也和EPUB内部保存格式一致。
具体步骤如下:
首先指明一点,以下的步骤最后要达到的排版上的目标是:所有图片都能正常显示,但都默认靠左(有些阅读器可以设定图片强制居中显示)。文字段落和图片分开,文字不会环绕图片,也就是不会左边一半是图,右边一半是文字。虽然那样效果更好,但难度太大,不易实现。
1、如果加密了,使用PDF Password Remover移除PDF文件加密限制。加密问题后面还会具体讨论。
2、用Acrobat打开,菜单中
文件,另存为(或导出),选择生成HTML3.2格式(无CSS)。生成的时候可能比较慢,一定要耐心等,不要乱点鼠标,容易死机。根据经验,这里不选择HTML4.0(CSS1.0),尽管后者有CSS的支持,排版按理说会更好,但事实上导入ePubBuilder中出错率大增,效果也并不好。
3、在浏览器中查看,有没有明显的错误,比如根本打不开,全是乱码,没有中文,没有图片等。全是乱码可能是HTML编码的问题,没有中文可能是PDF字体、编码的问题,没有图片或许是HTML链接的问题,解决起来很麻烦,也不一定对。如果真遇到这样的严重问题,我也无能为力了。不过幸运地是,只要PDF比较正常,不会出现这种问题。
这里简要说明一下,HTML一般由源文件和数据文件夹组成,如“摄影.html”和对应文件夹“摄影_files”,文件夹也有可能是其他名称,如images,源码和数据文件夹通常要放在同一父文件夹下,文件夹中主要为图片等多媒体文件,可能还有CSS样式表、Javascript脚本一类的东西,在PDF导出的HTML3.2中,基本上只会是图片。而html源文件其实是文本文件,用记事本就可以打开,后面我们会用Notepad++直接操作HTML源文件。
4、从这一步开始,我们需要修正HTML的各种问题,会涉及一些可能不好懂得知识。对于了解HTML和正则表达式的人,应该能很快明白。不懂的话照着做就可以了。如果你在上一步打开HTML时感觉排版已经很好了,而且没有多余的东西,可以直接跳过HTML修正的这些步骤,直接导入到ePubBuilder看效果如果。
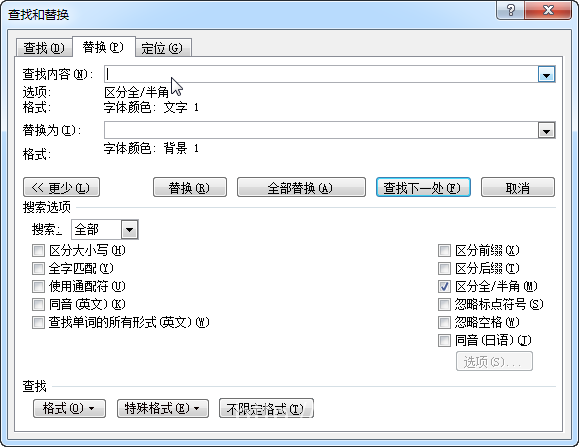
5、用Notepad++打开HTML文件,我们可以看到其源码如图。
6、替换删去html源码中align代码以去除图片文字指定的对齐,使其默认左对齐。具体方法是,按Ctrl+H,或菜单中 搜索 -
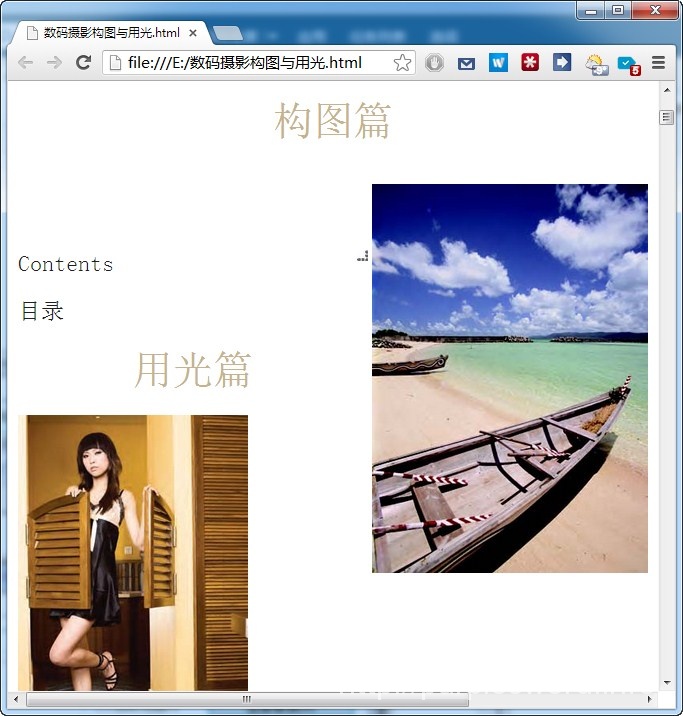
替换,“查找模式”为“普通”,“查找目标”为align=“center”,,“替换为”这个框不填,勾选“循环查找”,然后点击“全部替换”。如果一次处理多个文件,则全部打开,点击“替换所有打开文件”即可。同样,“查找目标”分别改为align=“left”,align=“right”,align=“justify”,全部替换。再次打开HTML时,你会发现原先位置有些混乱的图片看上去好多了。如果有些图片确实是居中更合适,可以不全部替换,或者在后文还会利用Word来修改。
这个版式就有点乱,原因就在于有些图片靠右对齐,有些靠左,还有的文字设定了两端对齐。
7、替换删去页眉等干扰图文(使用正则表达式)
一般的图书都会有页眉和页脚,例如图中红色框出的部分,还有像页码一类的标注。这些信息在生成EPUB后完全没有意义,因为EPUB在不同情况下页码分布并不一样。了解Word的人知道,在图书编辑时,页眉是可以批量编辑修改的,但是生成PDF之后页眉页脚变成了分别独立的对象,没办法同时删除。
如果页眉是文字,将在下一步处理,源码中有可能文本采用的是转义字符,看不懂的情况下也不便修改。如果页眉含有图片,如图中的数字02,需要通过HTML源码进行替换。方法如下。用Chrome和Notepad++同时打开HTML文件,在Chrome中右击页眉图片,审查元素,底下会有个显示源码的窗口,看清width和height后面对应的表示图片宽高的数字,切换到Notepad++,还是使用替换功能,首先把“查找模式”改为“正则表达式”,取消勾选“匹配大小写”,勾选“.
matches newline”,其他选项不变,查找目标为
<[^<>]*IMG[^<>]*width=“39”[^<>]*height=“71”[^<>]*>
注意中间没有任何空格,width和height后面的数字是刚刚在Chrome中看到的数字,然后全部替换,保存文件,但不要关闭Notepad++。这时,宽度和高度符合要求的图片就没有了。然后在Chrome中刷新,看修改后有没有问题,如果有问题,在Notepad++中撤销更改,然后得针对实际情况具体分析(此处略去)。一般在Chrome中还能看到一些页眉没有被替换掉,原因是他们的宽高可能与之前的有所差距,这时只需重复前面动作就行了。
采用转义字符(形如& # 20154 ;)表示的汉字,很难看明白:
8、用word进一步编辑
这一步完成后HTML就会接近完美了,所以也很关键。用Word打开HTML(不推荐其他软件,因为包含整本书的HTML文件一般很大,很多软件打开很容易死机,如WPS、DreamWeaver,而Word2010在这方面优化的不错,2003版的不清楚),打开后可以全选修改字体等,然后替换,去除少量无法显示的字符乱码,即显示为问号(同样注意尽量不要把原文问号替换没了),替换掉重复出现的网站信息、广告等,还有就是文字形式的页眉页脚(再次强调,注意尽量不要把原文中和页眉相同内容替换没了,Word中可以根据指定字体来替换,这样比较方便),对于不是很规则的页码如:第x页,这样的信息去除,则交给ePubBuilder来完成。然后用Word把图文中排版不当的进行适度修改,不需要的目录则去除,没有严重问题即可。注意这里有个问题,如果PDF比较完整,有目录,要把目录中对应页码删除。就像这样:前言………………………………………………………………1,这个第一页在转换为HTML时就已失去意义了,没有必要保留。
另外此处注意一种常见的问题,就是个别文字是图片形式保存的,将在后文常见问题中详细说明。
Word强大的替换功能,可以指定替换前后的文字格式。
9、如果有必要的话,优化HTML文件,以便正确导入ePubBuilder。
这一步事实上可以说应该还是ePubBuilder不够完善造成的吧,用Word编辑保存后的HTML文件头部会加入很多特殊信息,如图中<meta…>,还有绿色的部分(在标准的HTML中这种形式的文本为注释,删除后没有影响)等,另外还有图片的链接问题。这些问题有时会影响ePubBuilder导入,出现一些错误。如果出现了错误,请尝试使用浏览器打开另存,用Notepad++删除绿色的部分。
如果还是不行,使用用WPS新建文档(Word不行,WPS生成时会重新链接图片,Word则不会),用浏览器打开HTML,全选并复制网页内容,粘贴到WPS,保存为HTML。此时HTML文件会完全重新生成,但图片可能会被WPS转为png,占用空间一般会增大,不推荐。
10、如果用了WPS重新保存,请查看HTML文件的图片文件夹大小,如果过大,有必要压缩一下
压缩方法如下:
用数码照片压缩大师添加文件夹,输出jpg保存到另一文件夹,然后用Notepad++打开HTML源码,可以找到类似
<IMG 。。。 width=“711” height=“911” src=“images/img_0.png”
。。。>
这样的图片标签,然后用普通模式替换“.png”为“.jpg”。然后把图片文件夹的png图片删除,将压缩后的jpg移进去。最后用浏览器打开后确认一下。
11、用ePubBuilder导入,编辑书籍信息,分章节,智能排版等
看有没有错误,有错的话修改一下。前面可能还遗留了一个问题,页脚形如“第x页”的去除,可以使用删除特征行的功能实现。
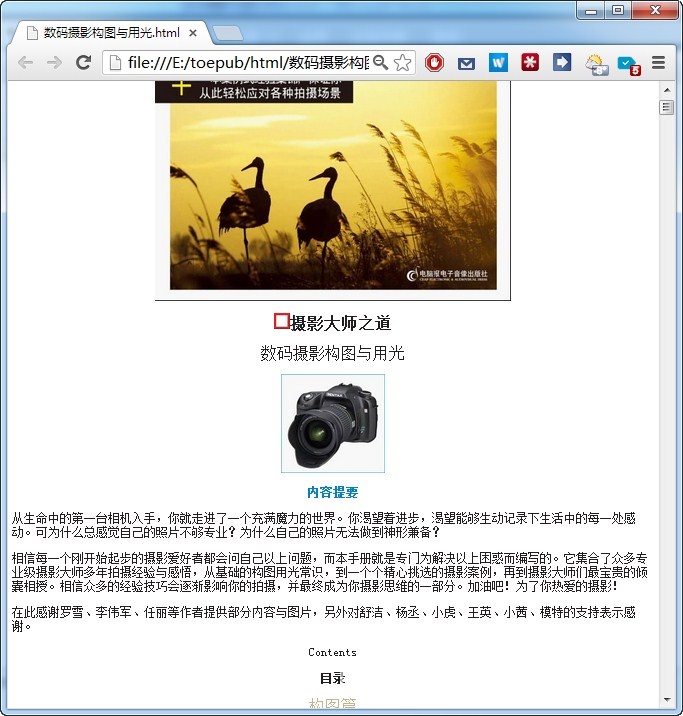
这里我还是提出ePubBuilder的一个缺陷。你可能会发现,原先的HTML排版很好,还有字体信息等,但导入后都没有了,有些图片也会有些小问题,比如我的HTML如图,但导入后,字体格式没有了,文字、图片居中没有了而且原先在“摄影大师之道”左边的那个红框位置就完全乱了,这个我目前还没有好的对策,期待着ePubBuilder功能继续完善吧。
12、导出EPUB,用掌上书苑或者其他查看器再查看一下是否正常。然后发布,等着审核通过拿书币吧^_^。是不是觉得这书币拿的格外开心呢?
容易出现的问题,我分析了以下,大致有这些吧:
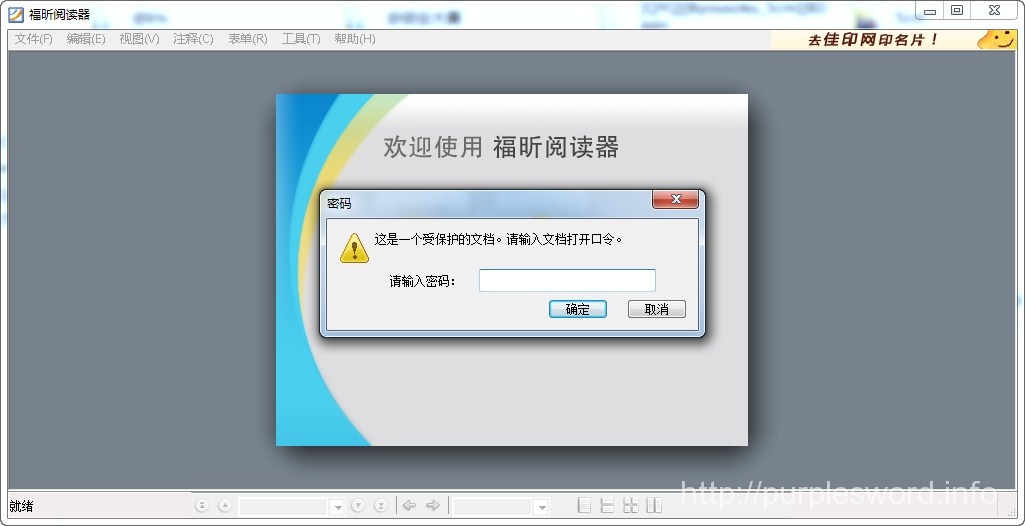
一是PDF的加密版权保护。很多PDF由于涉及版权问题,采用了一定的加密手段,最严格的一种是打开文件时要求输入密码,如图所示。对于这种情况,我们只能使用Advanced
PDF Password Recovery一类软件暴力破解,这里就不详细介绍了,成功率不高,需要大量时间。
更常见的加密方式是,文件可以打开,但不能复制其中的文本,或者复制的是乱码,这样的情况,我们使用PDF Password
Remover一般就能很快移除加密限制,从而复制其中的文本。
二是PDF内嵌的字体。很多PDF内嵌一些字体,会导致复制出来出现乱码现象。如果整个文档导出的文件错字连篇,我也不知有什么好办法,但是如果只有少量错字,还是可以手工修改的,或者某几个字出错,可以采用替换的方式解决,当然自动替换全部文字时很可能把正确的字给替换错了。举个例子,假设文中所有“的”字变成了“癿”,我们可以放心的替换回来,因为这个字很少见。但是如果“的”字全部变成了“白”字,盲目替换会把“明白”替换成“明的”,就出问题了。对于这样的情况,确实没有好办法解决。这一点尤其要注意。
还有一种情况,个别文字的字体系统中没有(通常是因为其他文字使用的字体不支持这几个字,这几个字就会换成其他字体),然后会被转换成图片,如图。这就需要在Word中耐心一点手动改正了。
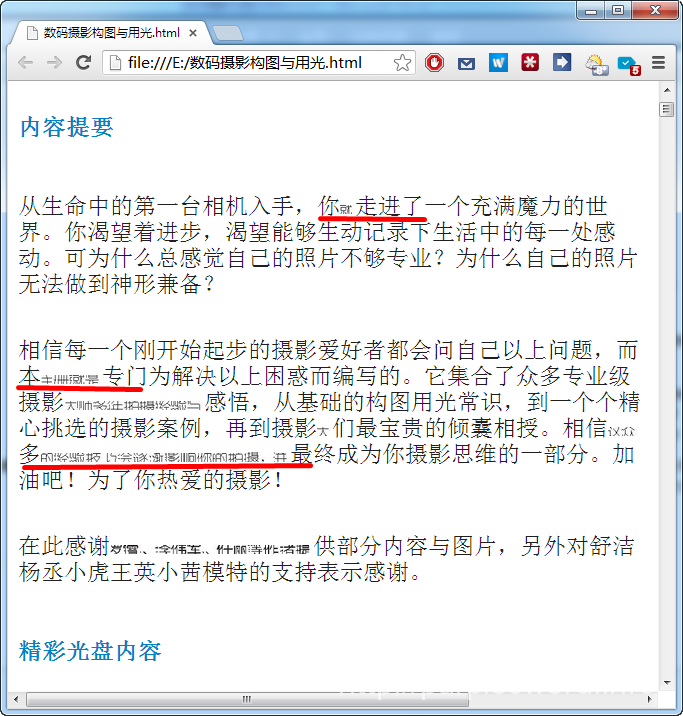
三是排版的问题。比如下面这边排版精美的摄影电子书,图文并茂,文字在图片中间,转换成HTML后会怎样呢?最后如你所料,有些混乱。这个也不好解决,如果你想制作优质的书,那就在Word中手动修改吧^_^。(很可惜我实在没有这般的耐心。)
还有一种情况,很奇特。在PDF中,文字也是一个个对象,通常一段字体相同的文字是一个对象。而每张图片是一个对象。但是,PDF编辑器有个很有意思的地方,比如说,两段文字原先是一个对象,你在其中插入一个空行,可能它就被分成两个对象了,反过来,两个同一性质的对象(都是文字或都是文字),靠得比较近时,又会自动并成一个对象。奇迹就发生了。试想,下图中假设中间的图和下面的图靠得很近,宽度也一致,然后就奇迹般地组合成一个对象了,然后输出的HTML中,他们成为了“连体婴儿”,成了一张图片,然后,你就不知道该怎么安排旁边那些描述性的文字了(除非手工又把图片分割开)。所以只好希望读者将就着看吧。哎,PDF转EPUB的无奈在此也可见一斑了。
